RDM

The professional handling of research data and the associated establishment of adequate research data management for the collaborative research center is one of the main tasks of CRC 1436.
We are developing an overall RDM strategy to manage the data from the different disciplines and structures within the CRC consortium, as well as to provide data sharing solutions that meet data protection requirements while ensuring cross-project collaboration. The final goal is the integration of the of the CRC1436 into the existing RDM structures and networks.
More details you can find in our CRC research data management concept.
What is the RDM?
Research Data Management (RDM) is vital in collaborative neuroscience research centers across partnering institutions in Germany to ensure accurate data, seamless collaboration, compliance with regulations, and the potential for data-driven discoveries. It enables efficient research processes, supports transparent and reproducible findings, and aligns with funding requirements and open science practices.
Within the intricate framework of SFB 1436, involving multiple participating institutions, substantial data volume, and intricate data sharing needs, Research Data Management (RDM) serves as a pivotal tool. It streamlines the research pipeline, untangling complexities, and fostering seamless collaboration by ensuring efficient data handling, structured sharing, and organized work flows.
Meta Data & Data-Management-Plans
Meta Data
Meta data in Research Data Management (RDM) for the neuroscience research center (SFB 1436) involves creating detailed information about the research data, such as its content, context, structure, and format. This meta data enhances data discoverability, supports collaboration among researchers, and ensures that the complex and intricate data sets in neuroscience are effectively organized and understood by both current and future stakeholders.
Data-Management-Plans
Data management plans (DMPs) in Research Data Management (RDM) for the neuroscience research center (CRC 1436) outline strategies for handling, organizing, and sharing research data. These plans ensure that the data is collected, documented, stored, and preserved effectively, promoting data integrity, collaboration, compliance with ethical standards, and the long-term value of research findings.
We have implemented the RDMO tool in the CRC 1436. Our pricipal investigators can use this tool to create separate data management plans for each project.
Data Transfer & FAIR-Principles
Data Transfer
The data transfer shows how the individual projects within the Collaborative Research Center 1436 are interconnected. The size of the network necessitates close networking of the sub-projects and a continuous exchange of information. This process is the basis for smooth data processing and requires responsible handling of all research data.

Gitlab
Central version management
- Logging and documentation of changes to versioned files
- Changes are traceable, traceable and can be restored at any time
- Can basically be used for all file formats
- Especially suitable for data in text format, program code or metadata such as XML or JSON
Nextcloud
Central data storage
- Access control – access to files and folders can be precisely defined for users, groups or external partners
- Changes, accesses and releases are logged and can be traced
Automatic version control
- For the first second we keep one version
- For the first 10 seconds Nextcloud keeps one version every 2 seconds
- For the first minute Nextcloud keeps one version every 10 seconds
- For the first hour Nextcloud keeps one version every minute
- For the first 24 hours Nextcloud keeps one version every hour
- For the first 30 days Nextcloud keeps one version every day
- After the first 30 days Nextcloud keeps one version every week
File sharing & collaboration
- Files or folders can be shared internally or externally (with password protection, expiration date, etc.)
- Collaborative working on documents (integrated Office)
FAIR-Principles
F- Findable: Data need to be findable. This is a prerequisite for further use and re-use of data. That means data and their respective metadata have to be easily findable both by man and machine. To fullfil this goal, the use of metadata such as for example title, author, index, description of methods, and the application of persistent identifiers (PIDs) like digital object identifier (DOI) is required. The usage of identifiers helps to keep data permanently findable as they are independent from URL changes.
A – Accessible: It is not enough, however, to render data findable. They also need to be accessible. That means data are archived in long-term storages and are accessible through technical standard protocolls such as https. Importantly, accessibility is not identical with open access, though information need to exist, in which way data are accessible, for example by stating contact information of the author.
I – Interoperable: Interoperable means that data need to be interchangeable using different applications and systems. Open data formats support this goal. In addition, it should be possible to combine and integrate data with other data from the same or even another research area. Metadata standards, standard ontologies, a set vocabulary and a meaningful link between data and their respective digital research object support unification.
R – Reusable: Last but not least, data need to be reusable. A prerequisite for sufficient reusability and recyclability is a comprehensive documentation of the data and their creation process following research area specific standards. Additionally, a licence needs to signifiy the terms and conditions for reusability.
(Copyright: UMMD / DIZ)
The life cycle of (research) data
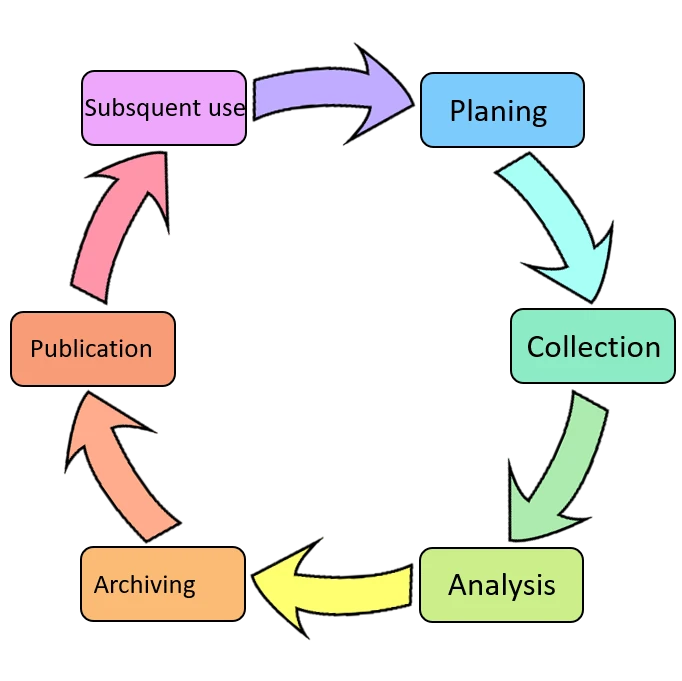
Planing: Contact your research data management team already at this phase! Solid planing is the basis for all further steps. Inform yourself about the prerequisites for research data management in the tender text of third-party funders and consult with your research data management team regarding data management plans.
Data collection: This step in the data life cycle is often the most tedious one, since here the actual data are being generated. No matter if observations, (image)data or the output from analytical devices – a detailed documentation of the data acquisition process is more than essential. It allwos for traceability of the whole process and helps to identifiy anf fix mistakes early on. It is important to also aquire standardized metadata, which also simplify later traceability. Documentation of data, their respective metadata and further information on the project should bedone in form of a (electronic) lab journal. On case existing data or probes are going to be used, legal rights have to be clarified beforehand. Mind the compliance with FAIR criteria for your data already at this phase.
Analysis: In order to interprete data and deduce results your entire knowhow and knowledge is needed. It is important that you apply common standards of your research area and document them as well. For yourself and the collaboration with your project partners it is significant that a shared system for data collection and data organisation is used. Processing and analysis of the data can comprise various steps such as digitalising, transcribing, examining, validating, cleaning, anynomising, statistical analysis and interpreting.
Archiving :The structure of the collected data again has effects on the data storage solution needed. Importantly, you should already think about long-term archiving and if access to stored data should also be granted to external project partners and collaborators. It is advisable that you inform yourself about availale data storage solutions offered by your local research data management. Take care to backup all your data and metadata to avoid data loss. Most raw data need to be stored for at least 10 years, depending on the type of data. Towords that end it is necessary that data migrate to long-living formats and that they and their backup are stored on long-living media. Additionally, data should follow open access rules and be made available via repositories to ensure long-term examination of scientific findings. Also here, your research data management team can be of help.
Publication: For this step of sharing/publishing defining access conditions is fundamental. These access rights and usage rights also contain the possible award of patents or licenses. In addition, the use of persisitent identifiers (PIDs) is advisable to help with unambigous identification and referensing. All CRC publications can be found here.
Subsequent use: All steps so far are not only meant to optimize data for own usage. Another aim should be to enable permanent usability for publication purposes and for the scientific community. Only then can a steady exchange between researchers and moving forward of science itself be ensured.
(Copyright: UMMD / DIZ)
Support & Request

Request and additional information
For CRC members
For external researchers
Request send to –